


WQUPC (Weighted Quick Union with Path Compression) reduces computation time from 30 years to 6 seconds.
In this story, we're going to discuss the importance of the union-find data structure (aka dis-joint sets) in our lives. We'll also discuss how we implement underlying operations and some additional tricks which can be used to further make our life easy.
Why do we care about Union Find?
Union-Find represents the array of problems that can be modeled as disjoint sets. If we consider two sets A and B such that intersection(A, B) = empty, that denotes that A and B are disjoint. The same principle applies when we deal with n number of elements. There are many possible real-life examples of disjoint sets:
- Social network (Find all the users which are connected directly or indirectly)
- Semiconductor conductivity (Are two points electrically connected?)
- Percolation (How many sites should be open before it percolates?)
- Pixels in a digital photo (Are two pixels in a digital maze connected?)
- and many more ..
Are two highlighted points connected in the maze below?

Now, we're slightly familiar with the importance of UF. Let's look at how it can be implemented using actual code examples.
Implementation
The basic API interface for a Disjoint set with Union-Find operations can be defined as follows,
class UF
__init__(N: int) # initialize a union-find data structure with N singleton objects (0 to N – 1)
def union(p: int, q: int) # add a connection between p and q
def find(p: int): int # component identifier for p (0 to N – 1)
def connected(p: int, q: int): bool # are p and q in the same component?
To implement UF using Quick-Find approach, consider the following premise:
- Integer array
id[]of lengthN. - Interpretation:
id[i]is parent ofi. - Root of
iisid[id[id[...id[i]...]]]
The Union Find queries can be translated to the above thought process, as
- Find -> What is the root of p?
- Connected -> Do p and q have the same root?
- Union -> To merge components containing p and q, set the id of p's root to the id of q's root.
class UF:
def __init__(self, n):
self.id = [0]*n
for i in range(n):
self.id[i] = i
def find(self, i):
while(i != self.id[i]):
i = self.id[i]
return i
def union(self, p, q):
idp = self.find(p)
idq = self.find(q)
if idp == idq:
return
self.id[idp] = idq
Isn't that very easy? That's the beauty of union-find, being powerful yet simple.
So, is it the best solution?
To answer these questions, let's see how much is the time complexity of the operations in the above-mentioned approach,
- Union -
O(N)- includes cost of finding roots - Find -
O(N) - Connected -
O(N)
Hence, a series of N union-find operations on a set of N sites takes O(N^2) time. The main factors contributing to worst-case in the above approach are:
- Trees can get tall (imagine a long chain of
id[id[id[...id[i]...]]]) - Find/connected too expensive (could be N array accesses).
Can we do better? To our surprise, yes we can use couple of interesting techniques for further optimizing union-find operations.
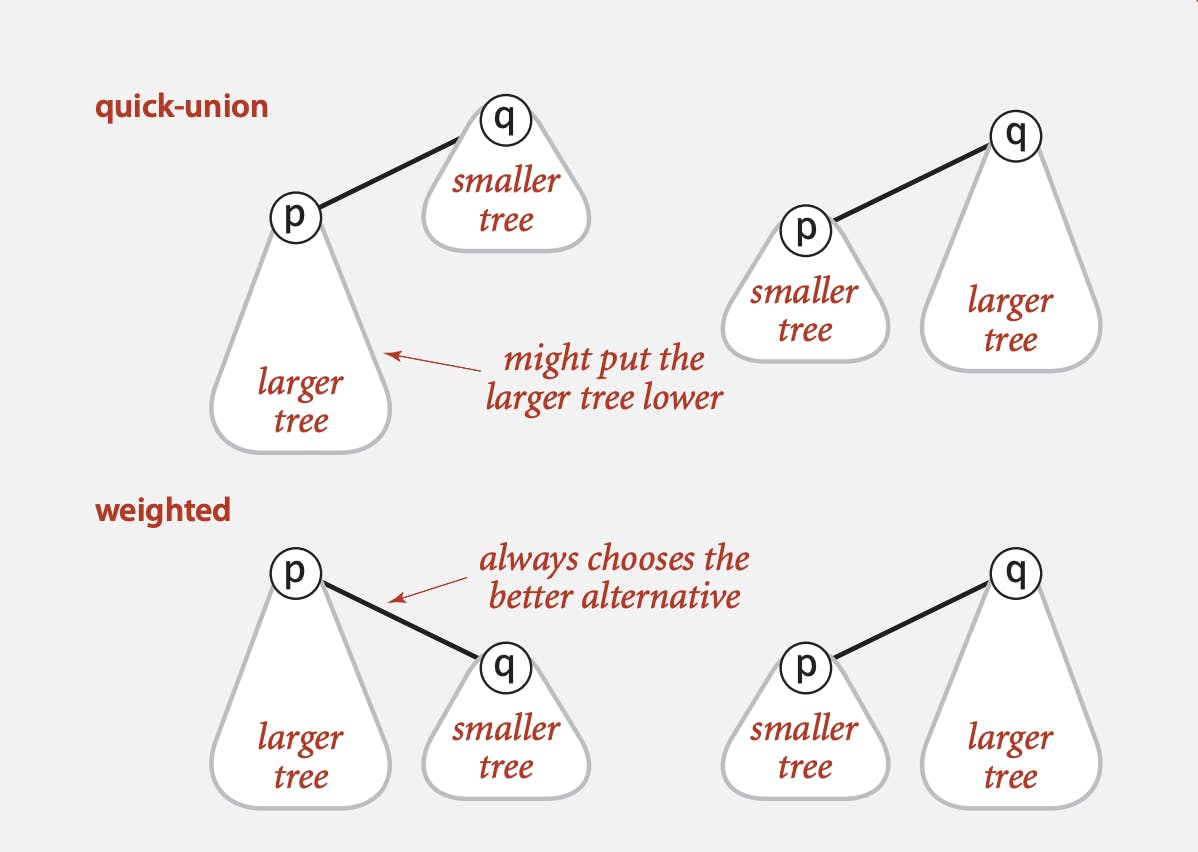
Weighting
In order to tackle the problem of having skewed trees, we can consider weighting.
- Modify quick-union to avoid tall trees.
- Keep track of size of each tree (number of objects).
- Balance by linking root of smaller tree to root of larger tree.
Path compression
We can modify the algorithm such that, subsequent queries are faster. Just after computing the root of p, set the id[] of each examined node to point to that root.
The easier way to implement that would be to every other node in the path point to its grandparent.
id[i] = id[id[i]]; # only single line of code
Optimized implementation
Incorporating above mentioned two tricks for further optimizations, we get WQUPC (Weighted Quick Union with Path Compression).
class UF:
def __init__(self, n):
self.id = [0]*n
self.weights = [1]*n
for i in range(n):
self.id[i] = i
def find(self, i):
while(i != self.id[i]):
i = self.id[i]
self.id[i] = self.id[self.id[i]]
return i
def union(self, p, q):
idp = self.find(p)
idq = self.find(q)
if idp == idq:
return
if self.weights[idp] > self.weights[idq]:
self.id[idq] = idp
self.weights[idp] += self.weights[idq]
else:
self.id[idp] = idq
self.weights[idq] += self.weights[idp]
Amortized analysis. Starting from an empty data structure, any sequence of M union-find ops on N objects makes ≤ c ( N + M lg* N ) array accesses. Where lg* N is an interactive log function.
- Analysis can be improved to
N + M α(M, N) - Simple algorithm with fascinating mathematics
Hence, In theory, WQUPC is not quite linear, however, in practice, it is linear. (iterated log function grows extremely slow, example - lg*(2^65536) = 5)
Interesting fact
For a famous example of performing 10^9 union-find operations on 10^9 sites/elements. Weighted Quick Union Find with Path Compression reduced the processing time from 30 years to 6 seconds. This unblocked solutions to a wide array of real-world challenges. It's a good example to demonstrate the importance of putting more emphasis on defining good algorithms.